LLM推理性能优化
PagedAttention
动机:LLM推理由两个阶段构成,prefill阶段和decode阶段,prefill阶段需要的kv cache占用是确定的,但是decode阶段并不知道需要多少内存分配,为了保证能生成,事先预留好最大的空间,但是最后可能会用不上,造成显存利用率低。
PagedAttention解决的问题:
- 如何动态为请求分配KV cache?
- 如果没有为每个prompt预留充足的显存空间,在某一时刻整个显存被打满,没有做完推理,怎么办?
PagedAttention的设计来自操作系统中虚拟内存的分页管理技术,
- 将物理内存划分为固定大小的块,每一块为页(page)。从物理内存中模拟出来的虚拟内存也按相同的方式做划分
- 对于1个进程,我们不需要静态加载它的全部代码、数据等内容。我们想用哪部分,或者它当前跑到哪部分,我们就动态加载这部分到虚拟内存上,然后由虚拟内存帮我们做物理内存的映射。
- 对于1个进程,虽然它在物理内存上的存储不连续(可能分布在不同的page中),但它在自己的虚拟内存上是连续的。通过模拟连续内存的方式,既解决了物理内存上的碎片问题,也方便了进程的开发和运行。
Prefix Caching 优化
Prefix Caching 是一种针对大语言模型(LLM)推理服务的创新性优化技术,其核心思想在于复用 KV Cache 中的 Token 缓存。当模型完成一个请求的计算后,系统不会立即释放其 KV Cache,而是将其暂存于缓存池中。当新请求到来时,系统首先在缓存中搜索与新请求 Token 序列的最长公共前缀(LCP)。若存在匹配前缀,则直接复用对应缓存中的 KV Cache,仅需对新增 Token 进行注意力计算和 KV Cache 更新,从而显著提升推理效率。
主要解决两个问题:
- 缓存管理机制:如何管理缓存 Tokens?应该保留哪些前缀?
- CUDA算子优化:能否针对 Prefix Caching 实现高效的 CUDA 算子?
Naive Batch Decoding Attetion
先考虑 MHA。对于 Attention 运算, 三个输入矩阵的 Shape
Q: (B,N,q_l,H)
K: (B,N,kv_l,H)
V: (B,N,kv_l,H)
其中 [B,N] 两个维度是 Batch 维度,可以并行计算, Attention 算子的 CUDA Kernel 会将 Grid Size 设置为 [B,N],一个 Thread Block 计算一个序列的单个头注意力。
decoding的时候,q_l=1,但是需要加载两个(kv_l, H)的矩阵,因此时Memory Bound的。
但是,在一个 Thread Block 中加载相同大小的 k、v 矩阵情况下,加载多个 q 矩阵,并计算多个q矩阵对应的结果,就能提升性能。
Radix Attention
SGLang: Efficient Execution of Structured Language Model Programs
Radix Attention 是一种基于 Radix Tree(基数树/前缀树) 和 LRU(Least Recently Used) 的缓存管理算法,主要用于高效管理前缀 Tokens(如自然语言处理中的词元或子词)。其核心思想是通过 Radix Tree 快速匹配最长前缀,并结合 LRU 策略动态更新和淘汰节点,以优化缓存空间利用率。
- 初始化
- 请求处理(匹配最长前缀)
- 新增token节点,子节点,更新前缀节点刚访问
- LRU淘汰机制(缓存空间不足时,通过颜色标记)
Prefill-Decode分离
Prefill阶段是计算密集型,Decode是io密集型。
在传统的 LLM 推理框架中,Prefill 和 Decode 阶段通常由同一块 GPU 执行。推理引擎的调度器会根据显存使用情况及请求队列状态,在 Prefill 和 Decode 之间切换,完成整个推理过程。
而在 Prefill-Decode 分离式架构(以下简称 PD 分离式架构)中,这两个阶段被拆分到不同的 GPU 实例上独立运行。
大模型推理的两个评估指标:
- TTFT(Time-To-First-Token):首 token 的生成时间,主要衡量 Prefill 阶段性能。
- TPOT(Time-Per-Output-Token):生成每个 token 的时间,主要衡量 Decode 阶段性能。
合并式架构
prefill和decode是合并在一起的,可以通俗理解成一块gpu上我既做prefill又做decode。
分离式架构
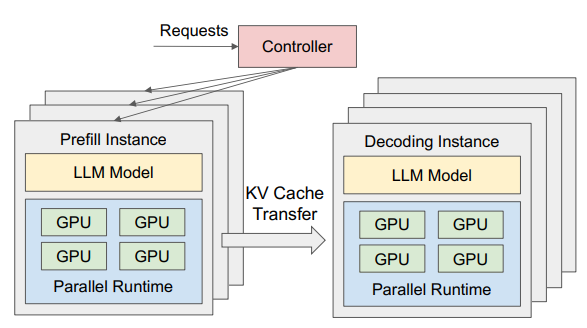
在分离式框架中prefill和decode不再共享一块/一群gpu,prefill实例计算完毕后,把产出的KV Cache传送到decode instance,然后decode实例继续做推理。
分离式架构相比于合并式架构,多加载了模型副本(耗显存),同时还涉及到gpu间的KV Cache传输(耗时间),为什么会更好?
重点是理解下面这个图,就能很好理解为什么要分离式架构了。
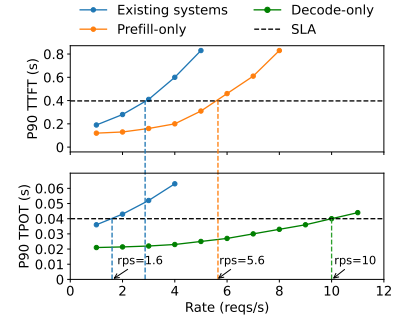
比如用两张卡做prefill,一张卡做decode。能得到rps=10,换算下来单卡rps=3.3,优于合并式的单卡1.6。
Prefill/Decode独立优化
- prefill阶段:(compute-bound),特别是在请求流量较大,用户的prompt也比较长的情况下。prefill阶段算完KV cache并发给deocde阶段后,理论上prefill就不再需要这个KV cache了(当然你也可以采用LRU等策略对KV cache的保存做管理,而不是一股脑地清除)。
- decode阶段:(memory-bound),因为token by token的生成方式,decode阶段要频繁从存储中读取KV Cache,同时也意味着它需要尽可能保存KV cache。
通过网格搜索,拟合 + 二分找到合适的prefill和decode配比,几张卡做decode,几张卡做prefill。
那么什么时候用张量并行,什么时候用流水线并行呢?对于prefill阶段,在请求rate较小时,更适合用tp;在rate较大时,更适合用pp。也即prefill阶段在不同条件下,对并行方式有倾向性。个人理解用tp换通信开销。
看到这里希望可以回答为什么使用P/D分离的方式。
Cascade Inference
共享前缀 Batch Decoding Attention CUDA 实现
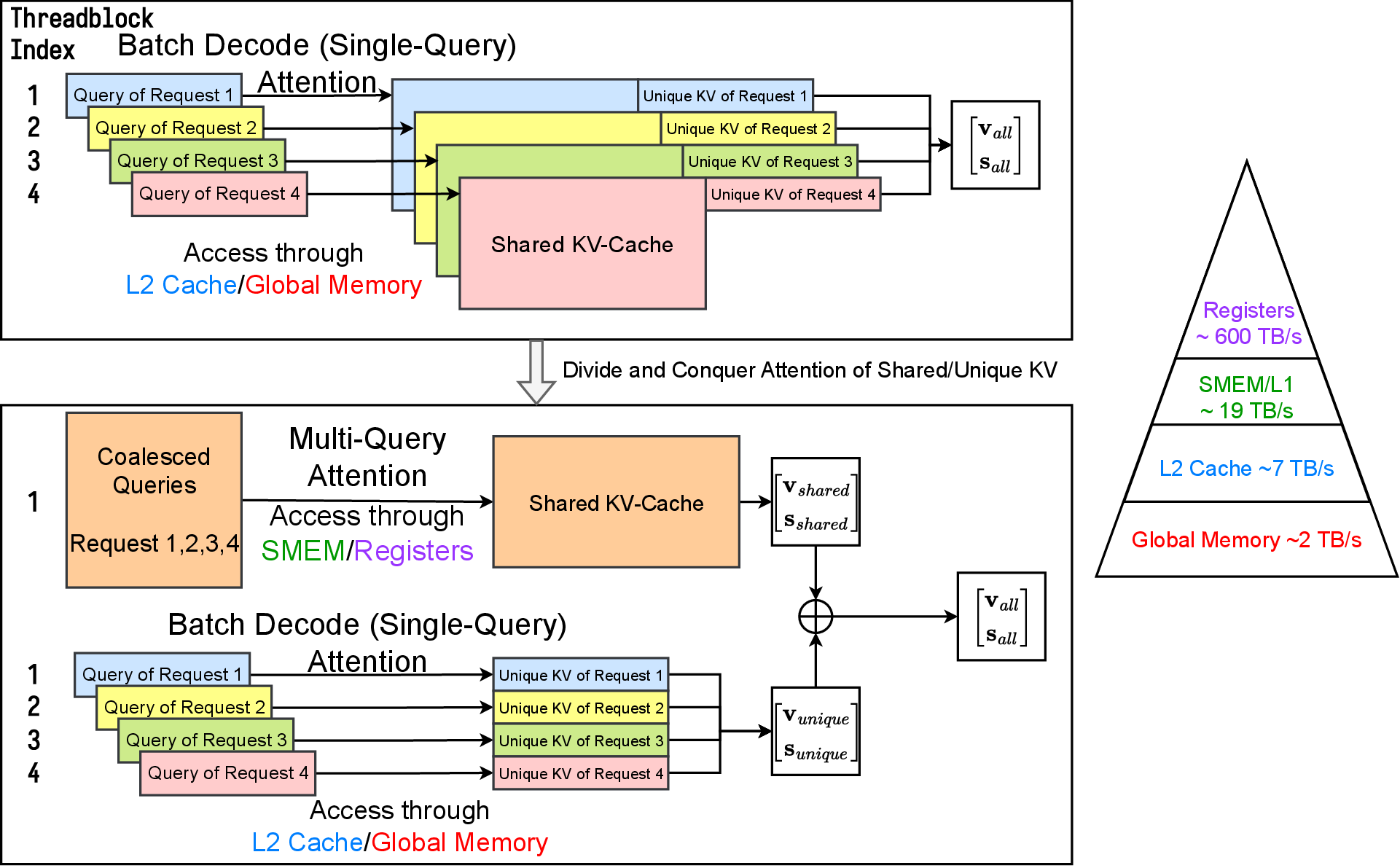
当 Batch Decoding Attention 所有输入请求的前缀完全一致时,输入的 Q 、K 、 V 三个矩阵的 Shape 分别为 (B,N,q_l,H)、(1,N,kv_l,H)、(1,N,kv_l,H)。类似 MQA ,GridSize 可以设置为 [N] ,那么一个 Thread Block 的三个输入矩阵 q,k,v 的 Shape 将为 (B\times q_l,H)、(kv_l,H)、(kv_l,H), 相比 MHA 实现提升了 B 倍,算术强度也提升接近B 倍,并降低访存开销。
推测解码
什么是推测解码?
推测解码的工作原理是使用更小、更快的模型来推测或提出潜在的未来标记,然后由更大的主模型进行有效的检查。
生成延迟仍然是现代 LLM 应用的主要瓶颈——它拖慢了聊天助手、编程工具和多步骤代理工作流程的速度。LLM生成内容的过程一个逐字decode的过程,漫长的等待不仅降低了生产力,限制了新兴AI的实际应用。
推测解码,通过并行预测和验证多个token提供了一个解决方案,大幅降低LLM agent的延迟。现有解决方案的一些缺陷:
- 未能利用agent应用中存在的重复生成模式,例如在自我反思、多重推理路径中,即使有许多重复的token,也只能预测少量的token。
- 缺乏一个简单且标准化的框架来训练自定义草稿模型并将其无缝地投入生产服务,而这对于推测开放式对话中常见的非重复生成模式至关重要。此外,系统级开销阻碍draft模型实现其理论上的峰值加速。
改进:
重复代理生成的后缀解码
非重复生成的推测训练和推理pipline
两者的最佳组合?
推测解码的三个步骤:
- Proposer:更小更便宜的语言模型,可以快速生成候选标记,不依赖模型,而是其他来源生成候选标记;
- Scorer:大型、高性能的LLM,不是只生成一个token,而是接受Proposer提出的一系列token,在一次前向计算中传递并并行评估多个token;
- Verifier:确定哪些token被接受
Speculative Decoding
Fast Inference from Transformers via Speculative Decoding
开山之作
Lookahead
SuffixDecoding
SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
有一篇博客:https://www.snowflake.com/en/engineering-blog/fast-speculative-decoding-vllm-arctic/
几个显而易见的结论:
Acceptance rate 越高说明draft模型可以很好预测目标模型的输出,这意味着每个验证步骤可以生成更多标记,从而提升速度。
Blanace acceptance和draft模型的成本,接受率和计算资源之间的关系是推测解码的基本权衡,更高的接受率有利于加快解码速度,但是也要考虑draft模型生成的计算开销,所以这是一个trade off的问题。
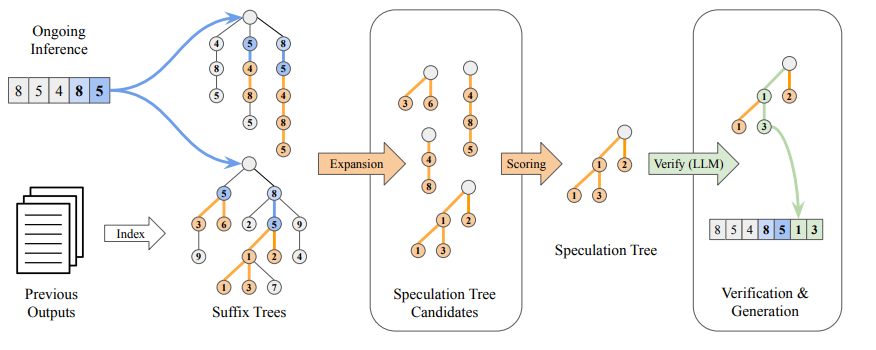
后缀解码的核心在于,使用一种名为后缀树的数据结构,对先前生成的序列进行紧凑的缓存。后缀树能够高效地索引和匹配来自历史生成和当前输入提示的重复标记模式,从而实现快速且自适应的推测。凭借这种优化的结构,后缀解码可以极快地推测标记 ,从而能够自适应地推测比以往更长的序列。
构建后缀树:过去几代历史输出和当前上下文提示,构建后缀树
推理时快速匹配,识别历史上遵循相似上下文的最长推测序列
基于频率的扩展,每个推测候选者基于频率,优先级排序,
并行验证,通过最小的计算开销接受正确的预测并丢弃不正确的预测
模型方式的推测解码,适用于重复性较低的场景
为什么基于后缀预测的推测解码,可以取得很好的效果?
- 生成的代码往往有一些错误,只需要进行微小修改即可修复
- 为了增强推理能力,采样多条推理路径,使得在每个步骤中多次查询LLM,并选择最佳相应,尽管这些推理路径各不相同,还是有大量的重复
Layerskip
开源了,后面的工作将其作为一个重要baseline
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
一个是关于大语言模型早退机制的研究,让模型用更少层来预测每个token,使用layer dropout方式,希望模型更多依赖前面的层,而不是后面的层,对于前面的层使用更低的丢弃率,后面的层更高的丢弃率。
之前的LM Head没有接受过更早期block输出的训练,因此在训练期间增加一个损失函数,使得LM Head更好理解早期block输出。这个LM Head是共享的。
提出了一种自我推测解码方法,其中我们使用早期退出来自回归地生成每个标记,并使用剩余的层并行验证一组标记并对其进行纠正。
KV cache的缓存复用,这是由于draft阶段,使用模型的前E层,验证阶段,使用剩余的L-E层,可以复用kv cache计算,以及退出层前Q的cahce,可以继续从E-1执行到最后一层L。
PipeSpec
PipeSpec: Breaking Stage Dependencies in Hierarchical LLM Decoding
流水线加速
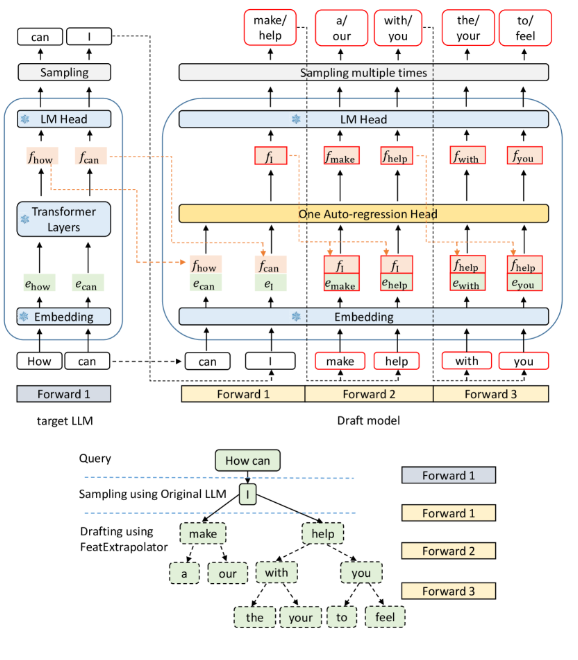
EAGLE
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
动机:
- 特征级别的自回归比标记级别的自回归更简单(输入信息多了)
- 采样过程中固有的不确定性严重限制了预测下一个特征的性能(需要上一个token的输出)
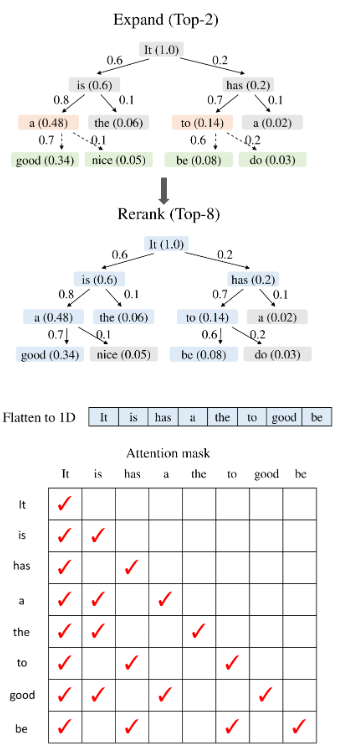
EAGLE2
通过draft模型的置信度,构建动态的树,在结束后对其剪枝;
动机:维护的树状结构,不同位置的token最后的接受率有不同,还取决于上下文
是不是可以剪去更多不会被接受的token,留下可能被接收的token,这样可以提升下游的接受率
EAGLE3
特征预测可以看作是一种额外的约束,它限制了draft模型的表达能力,并使其难以从增加的数据中获益;(不再要求draft模型的输出拟合目标模型的顶层特征)

SpecSearch
icml 2025
链接:https://www.arxiv.org/pdf/2505.02865
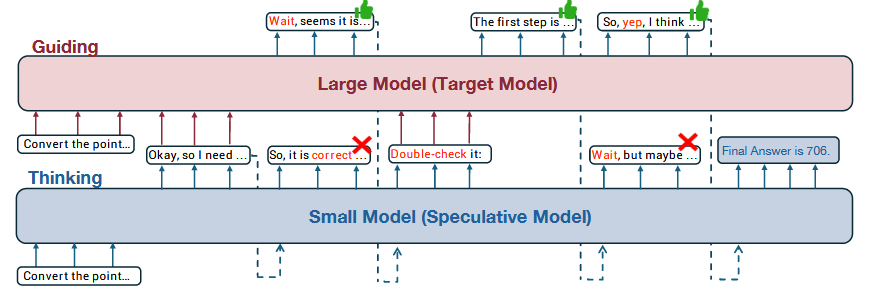
Speculative Thinking
一个无需训练的框架,使大模型在推理期间指导小模型,和speculative decoding这种在token级别运行的不同。
- “wait”经常出现,是一个信号,用于支持反思或继续生成
- 大模型相比于小模型,可以减少不必要的回溯反思,提升推理质量
效果:减少输出token,并提升精度
核心思想:需要两个模型,一个小模型(例如1.5B),一个大模型(例如32B),小模型在生成\n\n 或者 wait 这种token的时候,切换到大模型生成回溯反思,在生成结束后,在切换至小模型。
平衡了模型的推理速度和精度,但是最后精度达不32B的效果,但是速度可以有1-2倍的提升。