分布式RL训练框架
actor 在 RLHF 会进行 auto-regressive decoding,而 critic, reward 和 reference 则只会 prefill,不会 decode。所以,我们将 actor 的推理特定称为 rollout,而其他模型的推理称为 inference。
SPMD(单程序多数据)是一种并行计算编程模型,其核心思想是同一个程序在不同的处理器或计算节点上运行,但处理不同的数据。
为什么 PPO 的 rollout 引擎适合 SPMD?
因为training engine 采用 SPMD 而 rollout engine 采用 single controller 的话,所有训练节点的数据都必须汇总到某个控制节点上,才可以完成 training engine到 rollout engine 间的参数更新,这就不可避免地引入了通信瓶颈和单点故障风险。
改用 SPMD 的 Rollout Engine 后:
- 每个 GPU 可以独立模拟不同的环境或轨迹,减少中心化通信。
- 训练引擎(SPMD)和
rollout引擎(SPMD)之间可以直接点对点通信,避免单点瓶颈。
hybrid engine:在 RLHF 流程中,actor model 的 generation 和 rollout 占据了绝大多数运行时间(在 veRL 是 58.9%)。并且,由于 PPO 是 on-policy 算法,经验(experiences)必须来自于被 train 的模型本身,因此,rollout 和 training 是必须串行的。如果这两者使用不同的资源组,比如 rollout 用 2 张卡,而 training 用 4 张卡,rollout 的时候 training 的资源闲置,training 的时候 rollout 的资源闲置,无论如何都会浪费大量的计算资源。由此,veRL 将 training 和 rollout engine 放置在同一个资源组中串行执行。training 时,将 rollout engine 的显存回收(offload 到 CPU 上 或者直接析构掉),rollout 时,再将 training engine 的显存释放掉。这种将 actor model 的不同 engine 放置在同一个资源组上的方案,就称为 hybrid engine。
Route Map
博客
Pytorch Distribute
[原创][深度][PyTorch] DDP系列第一篇:入门教程
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
浅析以 OpenRLHF 为代表的 post-training 系统的计算流程
浅析主流 Alignment 算法与 NeMo-Aligner 框架
论文
DDP的基础原理
通过提高batch size来增加并行度,具体是通过Ring-Reduce的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。
- 假如我们有N张显卡,在(缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型参数在数值上是相同的
- 在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度
- 各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的
send-receive 模式
广播(Broadcast):广播是一种将数据从一个源进程发送到所有其他进程的通信操作。在 torch.distributed 中,通过 broadcast(tensor, src=0) 可以实现该操作,将 rank 为 0 的进程中的数据广播到所有其他进程。广播操作能够确保所有进程拥有相同的数据,适合需要共享模型参数、初始化权重等场景。
规约(Reduce 和 All-Reduce):规约操作是一种将多个进程的数据进行计算(如求和、求最大值等)的操作。常用的规约操作有两种,reduce():一个进程(通常是主进程)收集并合并来自所有进程的数据;all_reduce():所有进程同时得到合并后的数据。比如 all_reduce(tensor, op=ReduceOp.SUM) 会在所有进程中求和,并将结果存放在每个进程的 tensor 中。规约操作能有效减少通信负担,适用于大规模梯度汇总或模型权重更新。譬如在分布式训练中,all_reduce 常用于梯度求和,以确保在多个进程中的梯度保持一致,实现同步更新。
收集(Gather 和 All-Gather):收集操作是将多个进程的数据收集到一个或多个进程的操作:gather():将多个进程的数据收集到一个进程中。all_gather():所有进程都收集到全部进程的数据。例如 all_gather(gathered_tensors, tensor) 会将所有进程中的 tensor 收集到每个进程的 gathered_tensors 列表中。收集操作方便对所有进程中的数据进行后续分析和处理。譬如做 evaluation 时,可以使用 all_gather 来汇总各个进程的中间结果。
散发(Scatter):scatter() 操作是将一个进程的数据分散到多个进程中。例如在 rank 为 0 的进程中有一个包含若干子张量的列表,scatter() 可以将列表中的每个子张量分配给其他进程。适用于数据分发,将大型数据集或模型权重在多个进程中分散,以便每个进程可以处理不同的数据块。
张量并行与流水线并行
什么时候用张量并行,什么时候用流水线并行?
tensor parallelism 在单机多卡且卡间通讯强时较优;而 pipeline parallism 主要在多机情况下用于 serve 大到没法在单机上运行的模型。
pipeline parallism 是卡间通讯不好时唯一可行的 model parallelism 方法。
PP 将模型按照 layer 分开,每个 GPU 负责一部分 layer;而 TP将每个layer放在所有 GPU 上。PP 比起 TP 具有更好的 compute-communication ratio,因而不要求昂贵的卡间高速通讯
RLHF-PPO图解
PPO之所以被称为“近端策略优化”,是因为它采用了一种限制策略更新幅度的机制,确保新策略不会偏离旧策略太远,从而避免训练不稳定。
首先需要知道Actor Loss是什么,Critic Loss是什么,怎么推导的,这一点很重要,其次根据流程理解一下下面的图。
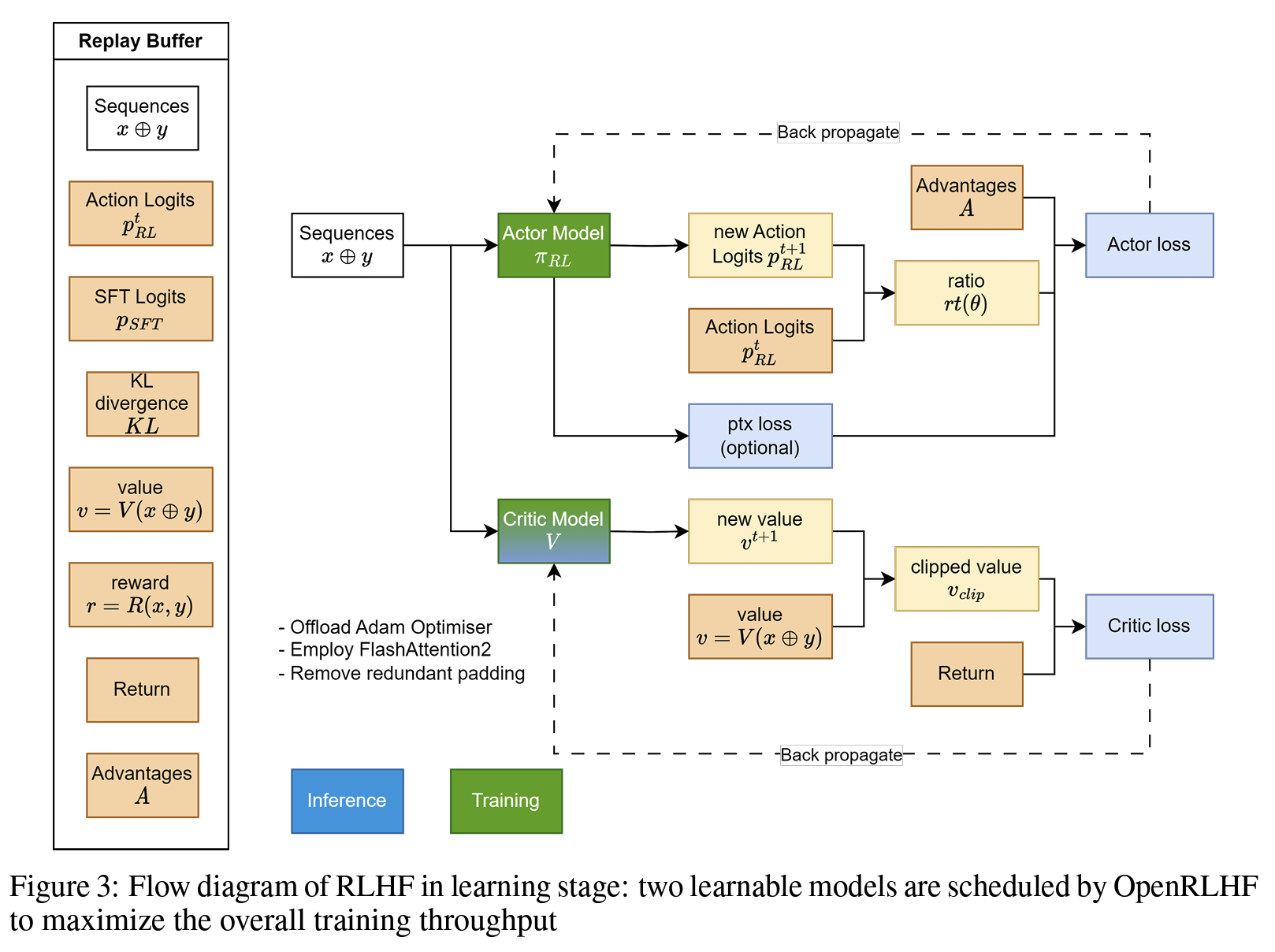
整体流程:
- 准备一个 batch 的
prompts; - 将这个 batch 的
prompts输入给 Actor,解码得到responses; - 将
prompt + responses输入给 Critic/Reward/Reference,分别计算得得到所有 token 的 values、最后一个 token 的 reward 和所有 token 的 log probs,按照强化学习的术语,称这些数据为经验(experiences)了; - 根据 experiences 多轮计算 actor loss 和 critic loss 并更新 actor 和 critic 模型。
对于第 4 步,我们当然可以一轮 experiences 就更新一次 actor 和 critic,但是为了尽可能利用这个 batch 的 experiences,我们对 actor 和 critic 做多轮更新。我们将 experiences 中多轮更新开始前的 log probs 和 values 称为 old log probs 和 old values(reward 不会多轮计算)。在每一轮中,actor 和 critic 会生成 new log probs 和 new values,然后在 old 的基础上计算 actor loss 和 critic loss,然后更新参数。
注意:只有actor是autoroll的,其他的三个模型都是prefill的
RL和SFT区别
引入了惩罚信号。众所周知,SFT只是模仿学习正例。而RL不仅对好的样本奖励,也要对坏的样本惩罚。无论是简单的策略梯度,还是GRPO、Reinforce、PPO这些算法,原理都是一致的,本质上只是在设计不同的奖励/惩罚的粒度(token/macro action/seq等等)和力度(需不需要引入baseline,要不要考虑KL限制,要不要clip等等)。
允许使用当前模型在线产出的样本训练自身。SFT一般学习的都是人工标注或者其他模型生成的样本(即蒸馏)。而RL允许当前模型实时采样样本,并依据这些样本训练自身。
- Rejection Sampling技术也是自己采样训练自己,为什么一般用在SFT阶段?
- 其实从这个角度来看,RS技术更像是RL,只不过没有惩罚信号(也可以引入负例进一步做DPO);
- on-policy vs. online:
- online强调当前策略模型是否能和环境进行交互(比如遇到新的一批数学题目,是否可以做完后实时拿到正确与否的信号),在一些其他场景(如GUI Agent,自动驾驶),允许online需要搭建复杂的simulator;
- on-policy强调当前的RL训练数据一定是最新的策略模型实时生成的,在一些时候,会预先采样生成大量的经验数据,然后分mini批次更新,在这种场景下,除了第一个mini-batch是on-policy的,后面的其实是off-policy的;
- 所以目前大家用的GRPO/Reinforce/PPO这些一定是online的,但不一定是on-policy(主要看mini-batch num是否大于1);
Ray
Ray 是一个分布式计算框架,现在流行的RL框架如VeRL和OpenRLHF都依托Ray管理RL中复杂的Roles(比如PPO需要四个模型)和分配资源。以下是一些核心的概念
- Ray Actor:有状态的远程计算任务,一般是被ray.remote装饰器装饰的Python类,运行时是一个进程(和PPO等Actor-Critic算法的Actor不要混淆了);
- Ray Task:无状态的远程计算任务,一般是被ray.remote装饰器装饰的Python函数,创建的局部变量仅在当前可见,对于任务的提交者不可见,因此可以视作无状态;
- 资源管理:Ray可以自动管理CPU、GPU、Mem等资源的分配(通过ray.remote装饰器或者启动的options参数可以指定指定的ray actor所需的计算资源),并且还可以设计资源组(placement group),将不同的ray actor指定放置在相同或者不同的资源位置(bundle);
- 通过使用ray,verl可以方便地实现各种角色、各种并行策略的资源分配,并且实现hybrid engine等colocate策略;
- 异步执行:ray的计算是异步的,一般执行一个ray的计算任务后,ray会立刻返回任务的执行句柄Object reference,用户的代码不会阻塞,可以自行使用ray.get/ray.wait进行阻塞式/轮询式的结果获取;
- PS: 在RL训练中引入异步的概念,可以方便actor/critic/generator/rm之间互相overlap掉一些处理时间(比如actor在更新上一个batch的时候,generator已经可以生成下一个batch了)。由于o1-liked rl的主要时间卡点在rollout位置,因此将rollout 更好地aynsc化(例如充分利用线上serving集群的夜晚空闲时间)是未来 rl infra优化的方向之一;
Chunck Prefill和Decoding
基于 chunked prefill 理解 prefill 和 decode 的计算特性
论文:SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
需要明确:chunked prefill 在数学上和不做 chunk 是完全等价的
核心技术:chunked-prefills and decode-maximal batching
占用度量:一个数据分布的概念
归一化的占用度量用于衡量在一个智能体决策和一个动态环境交互的过程,采样到一个具体的状态动作对(state-action pair)的概率分布。
占用度量有一个很重要的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
根据占用度量这一重要的性质,理解强化学习本质的思维方式:
- 强化学习的策略随训练不断更新,其对应的占用度量也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
- 由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励期望,因此寻找最优策略对应着寻找最优占用度量。
由此可以得到关键结论:
强化学习的目标是最大化智能体策略在和动态环境交互过程中的价值,策略的价值可以等价转换成奖励函数在策略的占用度量上的期望
例子
- 多臂老虎机
- 马尔可夫决策过程——当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质
马尔可夫决策
马尔可夫奖励过程:
回报G_t:所有奖励的衰减之和,给定一条采样序列,可以得到
价值函数:某个状态s的价值,当前状态的奖励输出,未来状态的奖励输出,可以当前状态的转移概率得到,这就是贝尔曼方程。
求解解析解的各个状态的价值时间复杂度是O(n^3),求解较大规模的马尔可夫奖励过程中的价值函数时,可以使用动态规划算法、蒙特卡洛方法和时序差分。
马尔可夫决策过程:
在马尔可夫奖励过程的基础上加入动作,就得到了马尔可夫决策过程
对不不同的策略来说,同一个状态下的价值是不同的
由于存在动作,因此额外定义一个动作价值函数,这个和状态价值函数的关系是?相乘再求和
使用策略\pi时,状态下采取动作的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积。
策略梯度
将策略参数化,使用一个神经网为这样一个策略函数建模,输入某个状态,输出一个动作的概率分布。最大化这个策略在环境中的期望回报。
log-likelihood trick,把期望的梯度变成了梯度的期望。
Actor-Critic
需要明确,Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。