大模型相关知识
BPE的原理?
子词分割算法,从字符级别开始,通过迭代合并频率最高的字符对(或字符序列)来构建新的 Token,从而可以处理部分 OOV(Out-Of-Vocabulary)情况。
- 初始化词汇表 V:
- V 包含语料库中的所有唯一字符,即单词字符的集合
- 统计字符对的频次:
- 对于每个单词的字符序列,统计相邻字符对的出现频次
- 找到频次(Score)最高的字符对并合并:
- 选择出现频率最高的字符对 (x,y),将其合并为新符号 xy
- 更新词汇表并重复步骤 2 到 4:
- 将新符号添加到词汇表 V=V∪xy。
- 更新语料库中的单词表示,重复统计和合并过程,直到满足停止条件(例如,词汇表达到预定大小)
Bert 模型讲一下,它的变种有哪些,做了那些改进呢?
- 仅Encoder
- 掩码语言模型,无标签文本双向表示
- 预训练+下游微调
- [CLS] 可以表征整个句子
- WordPiece进行分词
- mask训练策略
用过哪些 LLM?模型训练和推理占用显存如何计算?
以1B模型为例,32位浮点数,4GB大小
- 原始参数 * 1
- 梯度 * 1
- 优化器 * 2
LLM 推理阶段的参数有哪些,解释一下?
数据并行、模型并行和混合并行的工作原理?
数据并行:每张GPU拷贝一份完整的模型,不同GPU处理不同的数据子集,得到独立梯度,通过梯度同步,汇总所有卡的梯度,每张卡用相同的梯度更新参数
模型并行:层级切分/张量切分,通信开销大
混合并行:DP+PP,DP+TP等
为什么用sin/cos作为位置编码,可不可以用1,2,3...呢?
- 不同dim线性无关,避免信息荣誉
- 不同位置下的位置编码在点积后,只和距离差有关
大模型如何处理长文本输入?
递归树状结构/滑动窗口的方式
Llama 的中文能力不太行,怎么解决?中文词表扩充怎么做的?
关于中文扩充词表:https://www.zhihu.com/question/603607594
LoRA 的原理讲一下?为什么 LoRA 会有效果?LoRA 是怎么初始化的?LoRA 有哪些参数可以调整?
- LoRA:低秩分解来表示参数更新ΔW,在训练过程中冻结原始参数,仅训练A/B中的参数,一个全0初始化,一个高斯函数初始化。LoRA假设LLM根据下游任务微调得到的参数矩阵ΔW是低秩,可以近似表示/降维
- LoRA的参数:低秩矩阵的秩大小/缩放系数(控制对最终模型的影响程度)
为什么现在的LLM都是Decoder only架构?
- 注意力满秩的问题
- 预训练难度的问题
- prompt可以直接作用decoder层上
- 单向attention隐式位置编码
- 效率问题,kv cache的复用
- 轨迹依赖
LLM 做生成任务是怎么训练的?如果说做代码生成的任务你觉得应该怎么做?
如何做代码生成?先代码补全预训练,自回归任务如何做补全,分几部分重新排序,预测。指令微调(模型返回执行数据,通过加入,不通过不加入),同时要也要语言数据防止退化。
RLHF:Policy是LLM,action space是词表空间,observation是所有可能输入的序列
LLM 的涌现能力是什么原因,说一下你的理解?
- 任务的评价指标不够平滑;
- 复杂任务和子任务,子任务其实也在增长
- 需要最小数据量,减少过拟合,记忆中对原问题的干扰
LoRA
LLM的微调策略,发生在预训练权重矩阵更新上
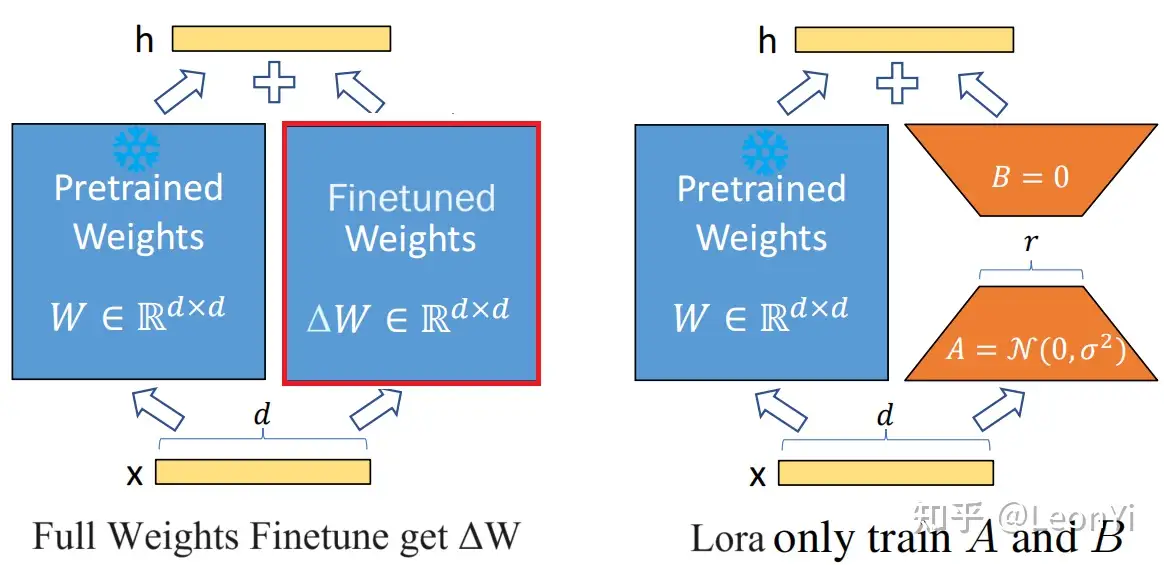
为什么A矩阵通过高斯函数初始化,矩阵B全0初始化?
高斯初始化是模型权重初始化的一种常见方式,均值为零、方差适中的初始化,可以保证信号在反向传播中稳步推进
A 和 B中有一个需要为0,保证旁路不影响原始权重,到底谁为0,可以做实验探究一下。
关于r的选择的经验,\alpha一般为r的两倍,太大学过头,太小学不动
强化学习
- reward normalize:使用历史获得过的所有 reward 的均值和方差进行标准化。
- token KL penalty:限制模型更新方向。
- Critic Model:使用 RM 初始化 Critic,并在 PPO 正式训练之前先进行 Critic 预训练。
- Global Gradient Clipping
- 使用相对较小的 Experience Buffer。
- Pretrain Loss:在 PPO 训练 loss 中加入 Pretrain Language Model Loss,和 [InstructGPT] 中保持一致